{{ secondMenu.name }}





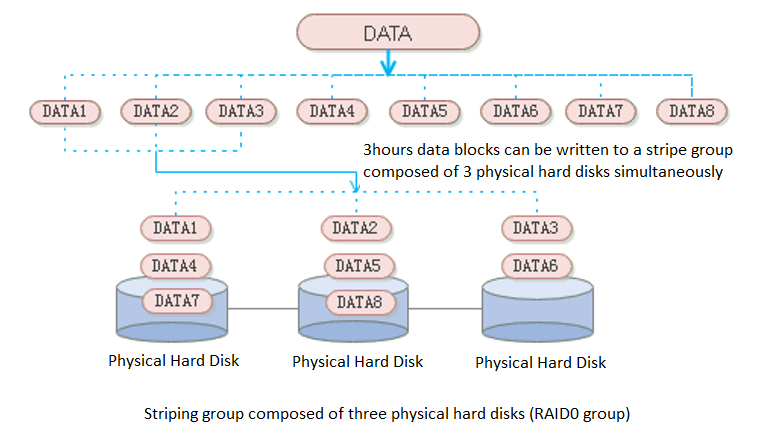
aSAN uses striping technology to maximize I/O concurrency. Stripping technology is to cut a piece of continuous data into many small data blocks and then stores them concurrently on different physical hard disks to achieve the maximum I/O concurrency when writing or reading data to obtain excellent performance.
As shown in the figure below, striped data can be written to three disks concurrently, while non-striped data can only be written to one disk at a time. Therefore, the writing performance of striped data is three times that of non-striped data.
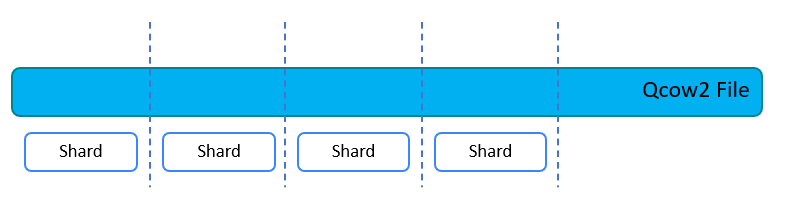
aSAN divides a single qcow2 file into several smaller pieces according to a fixed unit size through data fragmentation technology. Make data more evenly distributed in virtual datastores and data management more flexible.
Supports 2 Replica and 3 Replica for virtual machines carrying important business systems, users can choose to configure three replica policies to further improve the reliability of data. Support the conversion between 2 replica virtual machines and three replica virtual machines to achieve the best balance between high reliability and high performance.
Common storage strategies are built in the platform. Users can select corresponding storage policies when creating virtual machines according to the characteristics of business systems. At the same time, users can configure more detailed storage policies with the virtual machines as granularity according to the characteristics of the business system, which makes the configuration more flexible. Contains the following four attributes:
Replicas: Reliability index, two or three replicas can be selected according to the importance of the business.
Automated QoS: Performance indicators, including high performance, default performance, and low performance.
Strips Width: Performance index, the system will automatically set the number of strips or customize them according to the current storage state of the hard disk.
Replica Defrag: Performance indicator to ensure IO localization and improve read performance. An aggregate replica is enabled by default.
HCI supports the establishment of multiple storage subvolumes by selecting different nodes in a cluster. It meets the user's requirements for different services' capacity and performance isolation.
Host Multi Volume can only be supported when at least 6 hosts.
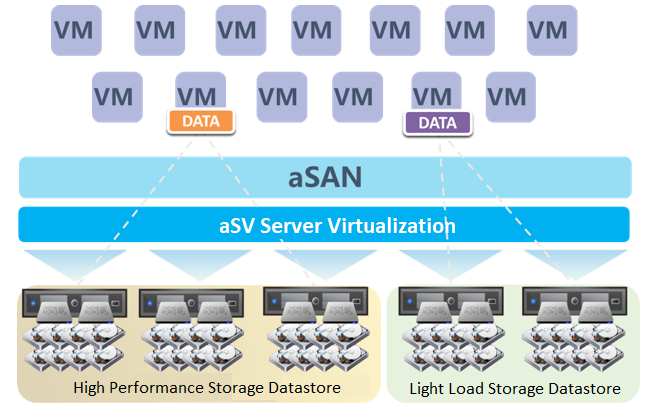
Dividing multiple volumes by host can only be supported when at least 6 hosts start. Small clusters with small business nodes cannot be divided into multiple volumes by node. However, multiple volumes can be divided by the hard disk.
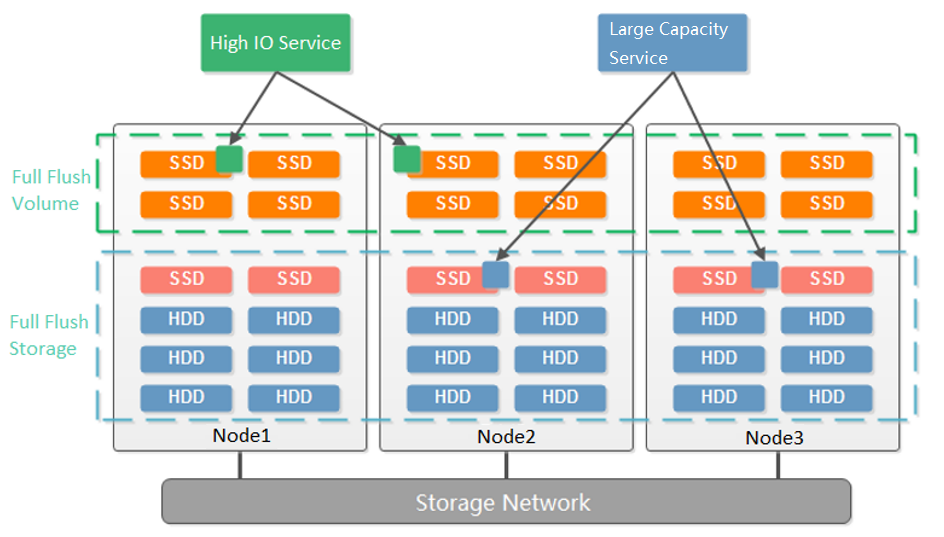
As shown in the figure below, starting from three nodes, aSAN supports dividing into two volumes according to the granularity of the hard disk. Compared with dividing virtual datastore according to nodes, it reduces the deployment threshold of multiple volumes. When customers have two types of services: high-performance and high-capacity, they can be divided into two volumes according to the hard disk: one flash volume + one hybrid volume. The flash volume runs high-performance services, and the hybrid volume runs high-capacity services.
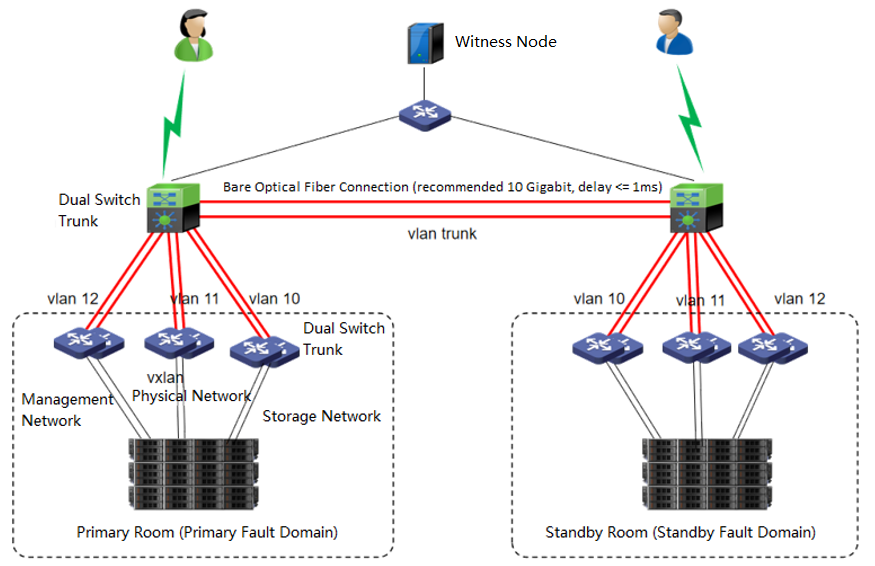
The dual-active data center is realized through the scheme of extending the cluster. The witness node must be deployed in this scheme to solve the split-brain problem and ensure data reliability. On average, the HCI node forms a cluster and is deployed to two machine rooms. Each machine room is configured as a fault domain, and each fault domain saves a copy. The data will be written to two copies simultaneously, and if any machine room fails, Data will not be lost.
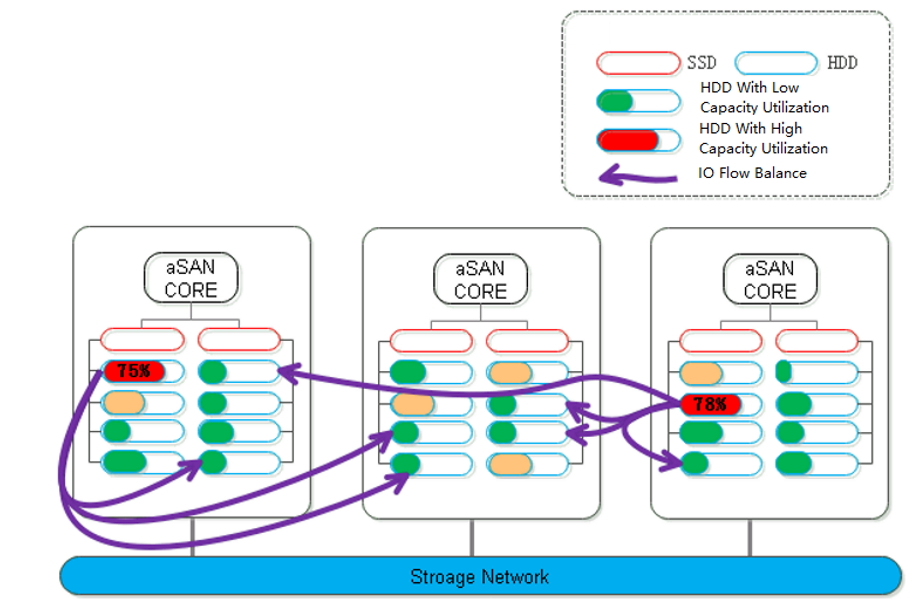
Data balancing refers to the automatic migration of some files from hosts or disks with insufficient virtual storage capacity to other hosts with ample storage capacity. Through the data balancing plan settings, components within the data storage volume can be evenly distributed during the planned time, ensuring that the space and performance of newly added disks or hosts are utilized efficiently and in a timely manner.
Data Balance Scenario:
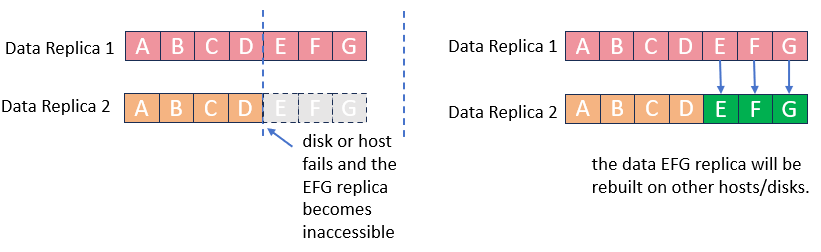
Through the data rebuilding function, after a component (disk or node) fails, aSAN will take another copy of the data on the failed component as the repair source, rebuild a new copy on the target component in the unit of fragmentation, restore the integrity, and realize system self-healing.
aSAN can provide standard iSCSI protocol, enabling aSAN storage resources to other physical servers or virtualization platforms (such as VMware) as pure external iSCSI storage. The iSCSI server of aSAN realizes the high availability and load balancing characteristics of the iSCSI server by redirecting the access IP to a virtual IP pool.
aSAN can find hidden bad sectors in time through the active scanning function of bad sectors to avoid the data being in the single-copy state for a long time.
When aSAN finds a bad sector, it will immediately trigger the repair of the bad sector data, read the data from another copy, repair it to the reserved sector of the bad sector disk, and recover the redundancy of the data copy in time.
aSAN actively migrates all data on hard disks with too many bad sectors (or SSD lifetime is about to run out) to other healthy hard disks in advance and always maintains the redundancy of replicas.
When the hard disk gets stuck, slows down, is congested, and under other abnormal conditions, it will affect the performance. At this time, the continuity of performance is guaranteed through sub-health disk isolation and read-write source switching.
Sangfor independently developed a high-precision bad sector prediction function by collecting and analyzing the SMART data, performance parameters, and hard disk log information of bad sector hard disks in many customers' actual scenarios, combined with advanced algorithm training models. The accuracy of aSAN's bad sector prediction is 95% above through many different business scenario tests.
aSAN can dynamically predict the capacity growth trend in the next 90 days according to the capacity usage of customer clusters. In the capacity prediction interface, the user can switch and view the raw capacity, actual used capacity, and dynamic prediction curve of different virtual datastore. It will prompt the user that the used capacity will reach the capacity alert threshold (90%) in XX days.
aSAN collects and analyzes the IO data of SSD hard disks in the cluster, calculates the remaining lifetime of SSD hard disks, and displays the expected remaining available time of SSD in combination with the upper business pressure. According to the prediction results, it is divided into three-lifetime levels: Healthy, Medium Risk, and High Risk. Notify users to replace the SSD hard disks in the cluster in time.
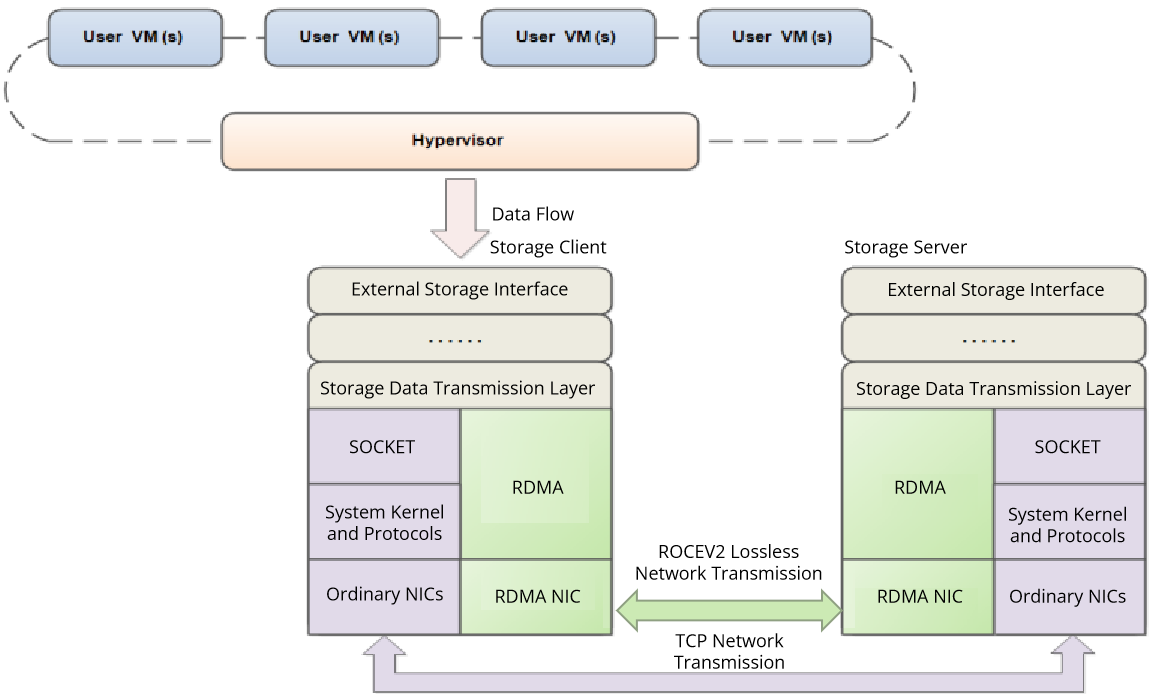
The demand for low-latency networking in today’s industries is growing, and operations such as system calls and memory replication cause huge performance overheads. Traditional network protocols (such as TCP and IP) are not designed for high-performance application scenarios and are unable to provide efficient communications. In this case, we use Remote Direct Memory Access (RDMA), the first network communication protocol used in high-performance computing, which enables computers to transfer data directly to each other’s memory without the intervention of the operating system, significantly reducing transmission latency and improving communication efficiency. Currently, RDMA is widely used in storage area networks, big data, and cloud computing with its zero-copy, kernel bypass, CPU offload, and low latency features.
RDMA is applied to the storage area networks of virtual storage platforms and is mainly deployed in the storage client and server processes to provide a mechanism similar to TCP for cross-node network communication. The RDMA feature can replace TCP for data transmission, lowering the network latency between the storage client and the server and dramatically increasing their throughput, which significantly improves the performance of virtual storage platforms.
![]()
1.Using RDMA requires configuring congestion control on the storage switch; otherwise, during peak business hours, performance may become slow or laggy.
2.Enabling or disabling RDMA requires interrupting services (shutting down VMs and network devices and disconnecting iSCSI connections). In production environments, a maintenance window must be approved before making this change.
3.If the storage network NIC model or firmware version does not support RDMA, the RDMA feature cannot be enabled. To verify if a NIC model or firmware supports RDMA, check the NIC vendor’s official website or the Sangfor official compatibility platform (for models that have passed internal testing).
4.RDMA networks are not supported in 2+1 cluster, two nodes cluster, Storage interface multiplexing, or stretched cluster scenarios.
5.HCI connections to external iSCSI storage do not support RDMA networks.
6.In multi-volume scenarios, RDMA is not currently supported for virtual machine access to virtual storage across volumes. This does not affect normal use; however, when VMs are scheduled to run on hosts in other volumes, performance may not be optimal but is still better than having RDMA disabled.
7.In multi-volume disk scenarios, two volumes on the same host must have RDMA either both enabled or both disabled. When the number of volumes differs across hosts, RDMA will first be enabled on the volume with more hosts, and smaller-volume sets will inherit the feature simultaneously. This restriction does not apply to hosts with multiple volumes.
8.Enabling an RDMA network consumes host memory. In configurations with 8 or fewer disks, there is no impact; with 24 disks, it consumes about 2GB of memory.
9.If the storage pool has RDMA enabled, any new or replacement host storage network interface must support RDMA; otherwise, expansion cannot be completed.
10.When upgrading HCI firmware version will impact the business.

 {{ $t('index.defaultHeader.chromeBrowserTip') }}
{{ $t('index.defaultHeader.chromeBrowserTip') }}