{{ secondMenu.name }}





Description
The HCI platform can automatically identify and display hosts' health, and for hosts that have been judged to be unhealthy, they will be downgraded when the virtual machine is powered on or HA is performed. For scenarios such as cluster capacity expansion and host replacement, hardware status is checked to avoid frequent node downtime or suspended systems due to hardware failures and to reduce business risks caused by hardware problems.
Precautions
Prerequisites
None.
Steps
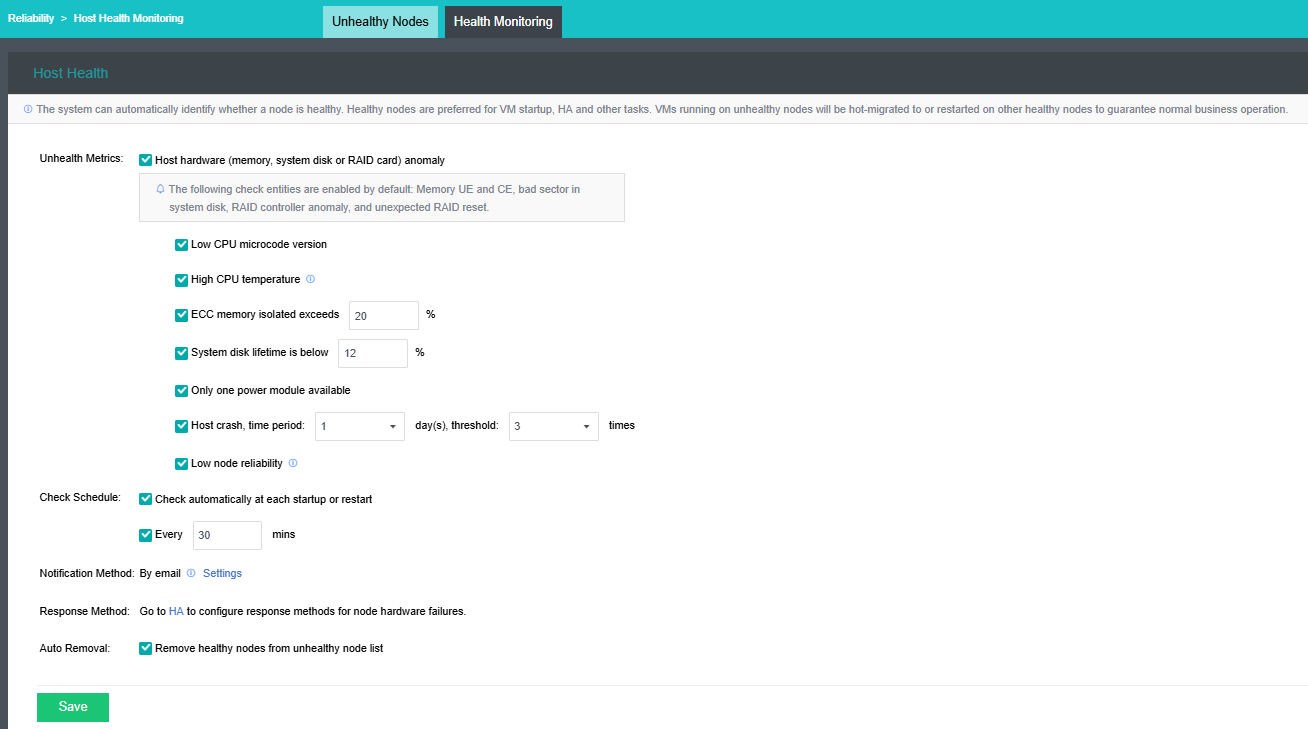
• Unhealth Metrics: If Host hardware (CPU, memory, system disk or RAID card) anomaly is enabled, the following will be checked: ECC Memory, UECC Memory, Bad Sector in System Disk, System Disk Read-Only, Short System Disk Lifetime Remaining, and RAID Card Failure. You can customize the crash frequency to identify unhealthy nodes that meet the criteria.
• Check Schedule: If Health Monitoring is enabled, the check will be automatically performed at each host startup or restart. You can also customize the check interval.
• Notification Method: You can go to aSecurity > Security Settings > Alert Options to configure the email notification by referring to Section 9.5.1 Alert Options. When an unhealthy node is detected, the platform will send an email to notify the check results.
• Recovery Method: You can go to Reliability > HA to configure recovery methods for host hardware failures.
• Fixing Method: This mechanism will only migrate VMs on unhealthy nodes to healthy nodes. VMs that have been configured with a scheduling policy are prioritized to be scheduled based on the scheduling policy, and VMs without a scheduling policy will only be migrated to unhealthy nodes that are relatively healthy. This mechanism does not take effect if there are no healthy nodes in the cluster and does not apply to NFV devices.
• Auto Removal: If enabled, unhealthy nodes will be automatically removed from the Unhealthy Nodes list when they are healthy again.

 {{ $t('index.defaultHeader.chromeBrowserTip') }}
{{ $t('index.defaultHeader.chromeBrowserTip') }}