{{ secondMenu.name }}
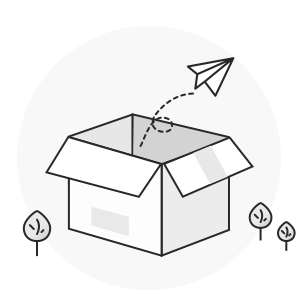





aSAN uses striping technology to maximize I/O concurrency. Striping technology is to cut a piece of continuous data into many small data blocks and then stores them concurrently on different physical hard disks to achieve the maximum I/O concurrency when writing or reading data to obtain excellent performance.
As shown in the figure below, striped data can be written to three disks concurrently, while non-striped data can only be written to one disk at a time. Therefore, the write performance of striped data is three times that of non-striped data.
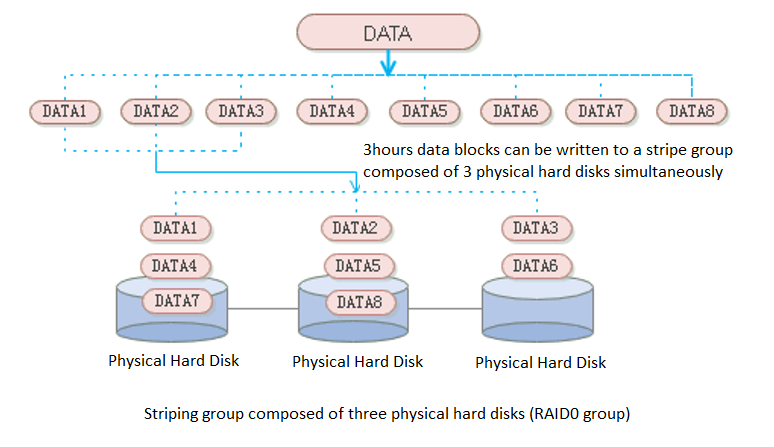
Zone
aSAN divides a single qcow2 file into several smaller pieces according to a fixed unit size through data fragmentation technology. Make data more evenly distributed in virtual datastores and data management more flexible.
Multi Replica Mechanism: Supports 2 Replica and 3 Replica
It also supports 2 replica and 3 replica policies. For virtual machines carrying important business systems, users can choose to configure three replica policies to further improve the reliability of data. Support the conversion between 2 replica virtual machines and three replica virtual machines to achieve the best balance between high reliability and high performance.
Common storage strategies are built in the platform. Users can select corresponding storage policies when creating virtual machines according to the characteristics of business systems. At the same time, users can configure more detailed storage policies with the virtual machines as granularity according to the characteristics of the business system, which makes the configuration more flexible. Contains the following four attributes:
• Replicas: Reliability index, two or three replicas can be selected according to the importance of the business.
• Automated QoS: Performance indicators, including high performance, default performance, and low performance.
• Strips WIdth: Performance index, the system will automatically set the number of strips or customize them according to the current storage state of the hard disk.
• Replica Defrag: Performance indicator to ensure IO localization and improve read performance. An aggregate replica is enabled by default.
Storage Snapshot
Supports the storage snapshot function. When creating a virtual machine snapshot, the system will set the source virtual disk as read-only and generate a corresponding number of new disk files (i.e., snapshot space).
After the snapshot is created, all new data and modifications to the source data of the virtual machine will be written to the newly generated snapshot space. The corresponding relationship between the logical address of the source virtual disk and the snapshot space will be written in the mapping table.
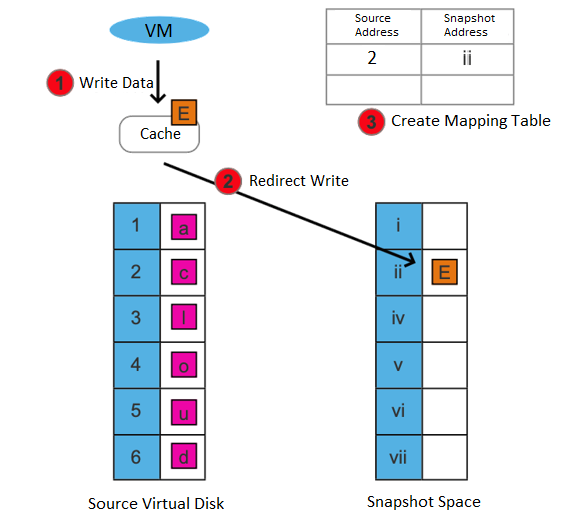
After the snapshot is created, there are two situations for the virtual machine to read data:
• If the data read is the existing data before the snapshot is created and has not been modified after it is created, it is read from the source virtual disk.
• If the read data is newly added/modified after the snapshot is created, it is read from the snapshot space.
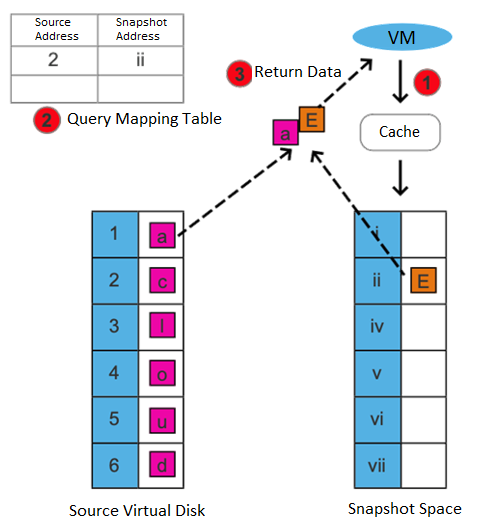
This snapshot method has the following advantages:
• Redirect on write (ROW) is used to realize the snapshot, and the virtual machine's performance will not be affected after the snapshot.
• After deleting a snapshot, you can free up storage space (initiate the snapshot residual file cleanup task).
Support consistency group snapshots to ensure the consistency of Oracle RAC and distributed services:
• Support adding virtual machines in Oracle RAC or multiple virtual machines hosting the same business system as consistency groups. Take snapshots for consistency groups to ensure that all virtual machines in the group take snapshots simultaneously.
• When the virtual machine in the consistency group fails, the virtual machine in the group can be rolled back to a consistent state by using the consistency group snapshot.
Support scheduled snapshots, simplify operation and maintenance, and make data more reliable:
• Support custom scheduled snapshot policies for individual virtual machines and consistency groups.
• The snapshot frequency can be selected by hour, day, and week. At the same time, to avoid frequent snapshots occupying a lot of storage resources, you can set the snapshot automatic cleaning policy. The system will automatically merge snapshot points and effectively use storage space.
• In the development test scenario, scheduled snapshots can greatly simplify operation and maintenance and improve data reliability.
Virtual Machine Cloning
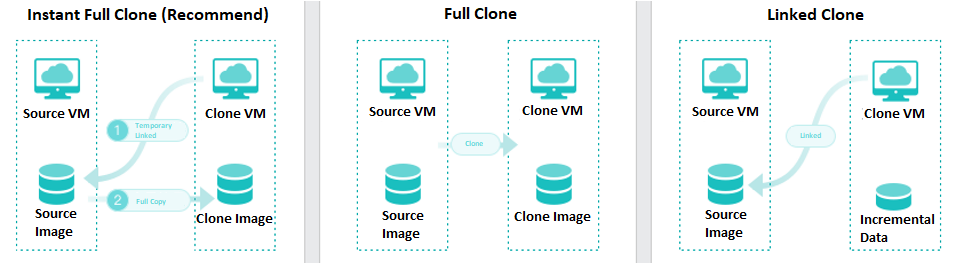
On the basis of full cloning of virtual machines, it supports both link cloning and fast full cloning of virtual machines.
The virtual machine generated by the linked-clone always depends on the source image to start and run. When the data is added or changed, it will be recorded and redirected to the new image. It has the characteristics of fast virtual machine startup, non-independent data, saving storage space, and performance will still be affected after cloning.
The virtual machine-generated by fast full cloning depends on the source image in the early stage and can be started in seconds. After the virtual machine start, the data will continue to be cloned, and the final data will be complete and independent. It has the characteristics of a fast virtual machine startup, final independent data, and no impact on the performance after cloning.
The virtual machine clone type can be flexibly selected, and the fast full clone type is recommended by default.
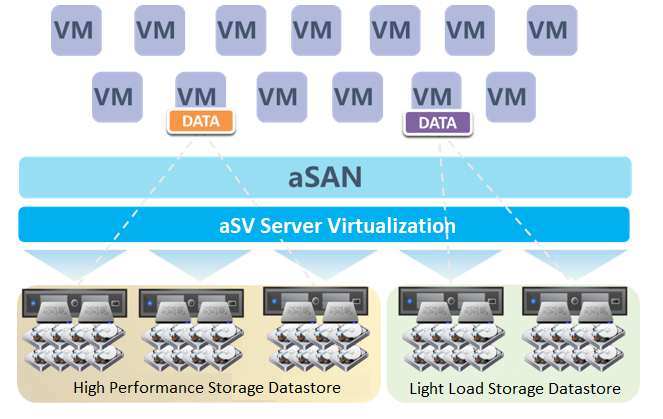
Host Multi Volume
HCI supports the establishment of multiple storage subvolumes by selecting different nodes in a cluster. It meets the user's requirements for different services' capacity and performance isolation. Also, it enables the business to switch between different storage subvolumes to realize the different performance requirements of the same business at different stages.
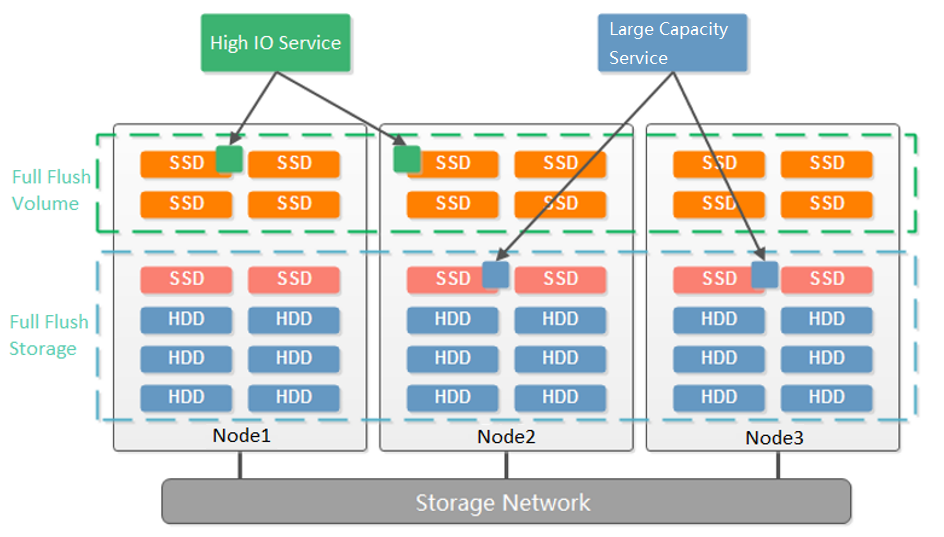
Disk Multi Volume
Dividing multiple volumes by host can only be supported when at least 6 hosts start. Small clusters with small business nodes cannot be divided into multiple volumes by node. However, multiple volumes can be divided by the hard disk.
As shown in the figure below, starting from three nodes, aSAN supports dividing into two volumes according to the granularity of the hard disk. Compared with dividing virtual datastore according to nodes, it reduces the deployment threshold of multiple volumes. When customers have two types of services: high-performance and high-capacity, they can be divided into two volumes according to the hard disk: one flash volume + one hybrid volume. The flash volume runs high-performance services, and the hybrid volume runs high-capacity services.
Extended Volume
The dual-active data center is realized through the scheme of extending the cluster. The witness node must be deployed in this scheme to solve the split-brain problem and ensure data reliability. On average, the HCI node forms a cluster and is deployed to two machine rooms. Each machine room is configured as a fault domain, and each fault domain saves a copy. The data will be written to two copies simultaneously, and if any machine room fails, Data will not be lost.
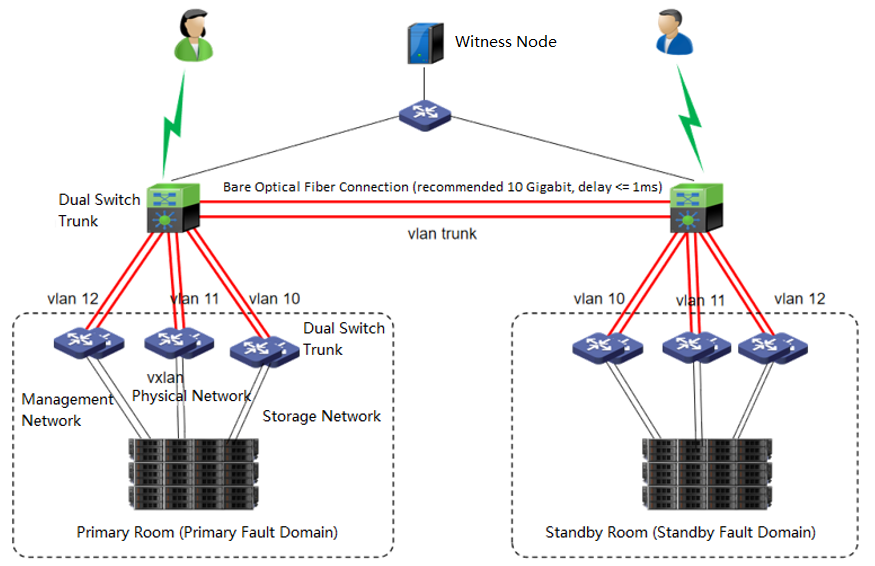
Data Balance
During distributed storage, the disks between nodes may also be used unevenly. When it is found that the difference between the highest and lowest disk capacity utilization in the volume exceeds a certain threshold, aSAN will calculate the location of each partition on the source side disk and the destination side disk it is about to fall into. The number of destination disks can be multiple; the location can be other disks in the node or disks in other nodes.
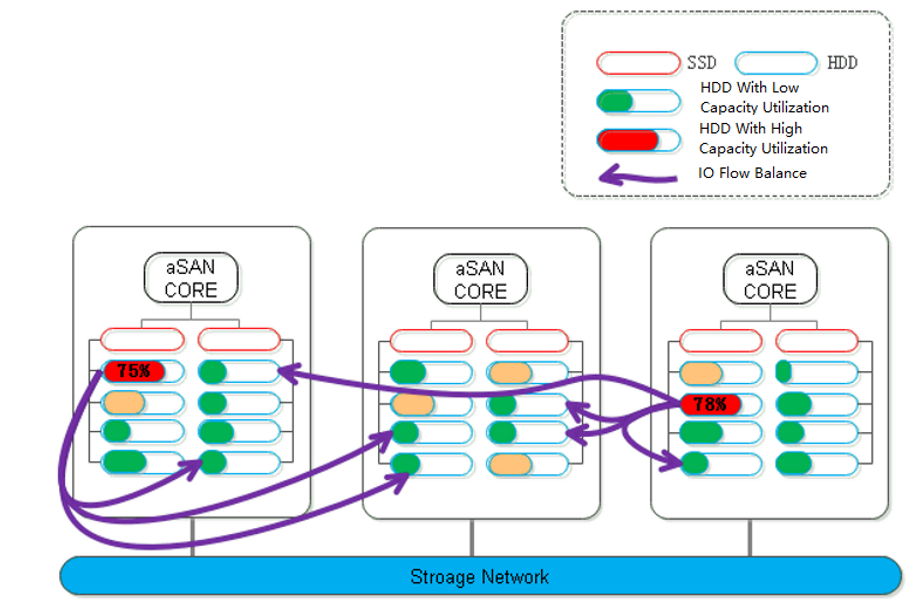
Data Rebuilding
Through the data rebuilding function, after a component (disk or node) fails, aSAN will take another copy of the data on the failed component as the repair source, rebuild a new copy on the target component in the unit of fragmentation, restore the integrity, and realize system self-healing.
Virtual iSCSI Technology
aSAN has virtual iSCSI technology. It can create a virtual iSCSI hard disk and supports access from a virtual storage network interface.
Heterogeneous storage management
• HCI supports adding FC storage and iSCSI storage as external storage, placing the datastore of virtual machines on FC storage or iSCSI storage, and realizing the HA function of virtual machines.
• HCI supports adding NFS as the backup location of virtual machines.
• HCI supports adding local or on-server disks other than the server system disk. After the RAID is formed, the logical disk is used as the virtual machine's datastore, but the virtual machine's HA function is not supported.
Disk Sub-health Scanning And Repair
• aSAN can find hidden bad sectors in time through the active scanning function of bad sectors to avoid the data being in the single-copy state for a long time.
• When aSAN finds a bad sector, it will immediately trigger the repair of the bad sector data, read the data from another copy, repair it to the reserved sector of the bad sector disk, and recover the redundancy of the data copy in time.
• aSAN actively migrates all data on hard disks with too many bad sectors (or SSD lifetime is about to run out) to other healthy hard disks in advance and always maintains the redundancy of replicas.
• When the hard disk gets stuck, slows down, is congested, and under other abnormal conditions, it will affect the performance. At this time, the continuity of performance is guaranteed through sub-health disk isolation and read-write source switching.
Bad Sector Prediction
We independently developed a high-precision bad sector prediction function by collecting and analyzing the SMART data, performance parameters, and hard disk log information of bad sector hard disks in many customers' actual scenarios, combined with advanced algorithm training models. The accuracy of aSAN's bad sector prediction is 95% above through many different business scenario tests.
Capacity Prediction
aSAN can dynamically predict the capacity growth trend in the next 90 days according to the capacity usage of customer clusters. In the capacity prediction interface, the user can switch and view the raw capacity, actual used capacity, and dynamic prediction curve of different virtual datastore. It will prompt the user that the used capacity will reach the capacity alert threshold (90%) in XX days.
SSD Lifetime Prediction
aSAN collects and analyzes the IO data of SSD hard disks in the cluster, calculates the remaining lifetime of SSD hard disks, and displays the expected remaining available time of SSD in combination with the upper business pressure. According to the prediction results, it is divided into three-lifetime levels: Healthy, Medium Risk, and High Risk. Notify users to replace the SSD hard disks in the cluster in time.
SPDK-Based Turbo Service
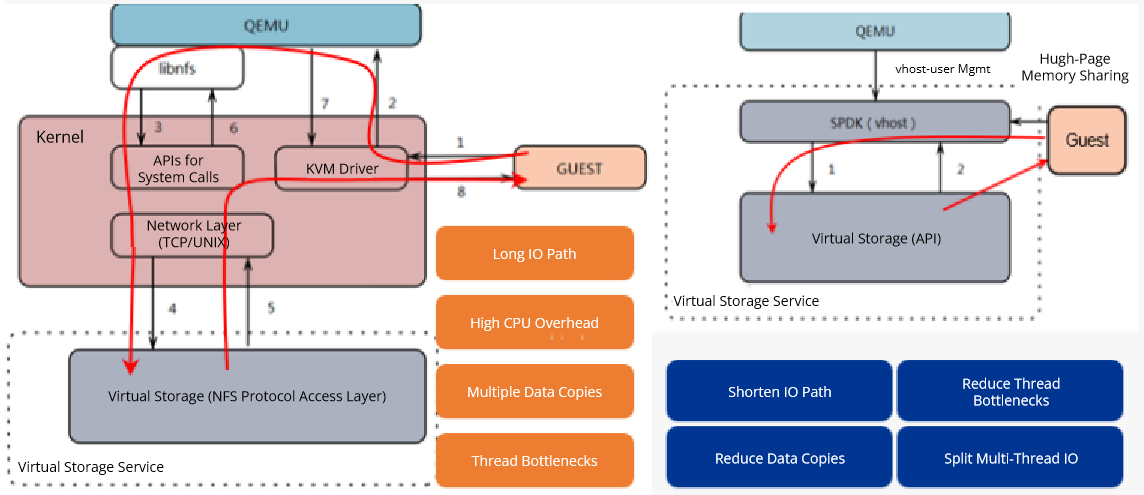
HCI carries many customers’ critical business services, including database applications, big data analytics, artificial intelligence, and machine learning. These services require high storage IO performance, which is directly associated with service processing speed and user experience. For this reason, we integrated HCI with the SPDK solution, significantly improving the performance of VMs running IO-intensive services.
The Storage Performance Development Kit (SPDK) is a toolkit for building high-performance storage applications. HCI uses the SPDK vhost at the virtualization layer to enable VMs to run in user mode so that IO streams can bypass the kernel to directly access the hardware, reducing the resources consumed by scheduling. The Turbo service based on SPDK vhost reduces the average latency of reading and writing large blocks of VMs from 4 ms to 2 ms, improves throughput efficiency by about 50%, and IOPS of small blocks by more than 20%, resulting in a significant increase in performance.
We deeply optimized the process of SPDK for accessing virtual storage, enabling IO at a single depth to directly access virtual storage in the context of round-robin threads, which reduces thread switching overhead, and switching IO at different depths to pipe threads to divide large blocks into multiple IO requests of 128 KB to concurrently process them. The IO performance test shows that compared to the original solution, the VM performance has been improved by 20% to 50%. We also transformed the SPDK framework to make it adapt to advanced features such as double instance checks, HA, and in-place active upgrades for VMs, ensuring a smooth SPDK VM experience.
Ordinary VMs and VMs using SPDK can coexist on HCI and convert to each other. You can choose whether to use SPDK based on the VM services, enabling a balance of performance and functionality.
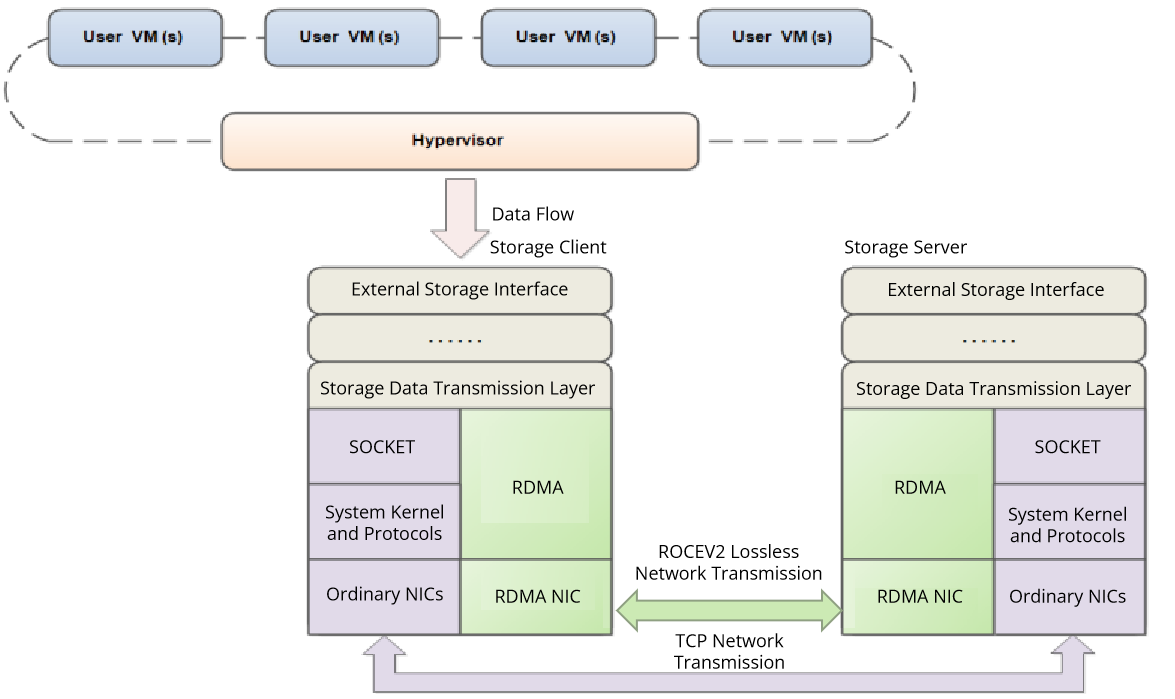
RDMA
The demand for low-latency networking in today’s industries is growing, and operations such as system calls and memory replication cause huge performance overheads. Traditional network protocols (such as TCP and IP) are not designed for high-performance application scenarios and are unable to provide efficient communications. In this case, we use Remote Direct Memory Access (RDMA), the first network communication protocol used in high-performance computing, which enables computers to transfer data directly to each other’s memory without the intervention of the operating system, significantly reducing transmission latency and improving communication efficiency. Currently, RDMA is widely used in storage area networks, big data, and cloud computing with its zero-copy, kernel bypass, CPU offload, and low latency features.
RDMA is applied to the storage area networks of virtual storage platforms and is mainly deployed in the storage client and server processes to provide a mechanism similar to TCP for cross-node network communication. The RDMA feature can replace TCP for data transmission, lowering the network latency between the storage client and the server and dramatically increasing their throughput, which significantly improves the performance of virtual storage platforms.

 {{ $t('index.defaultHeader.chromeBrowserTip') }}
{{ $t('index.defaultHeader.chromeBrowserTip') }}