{{ secondMenu.name }}





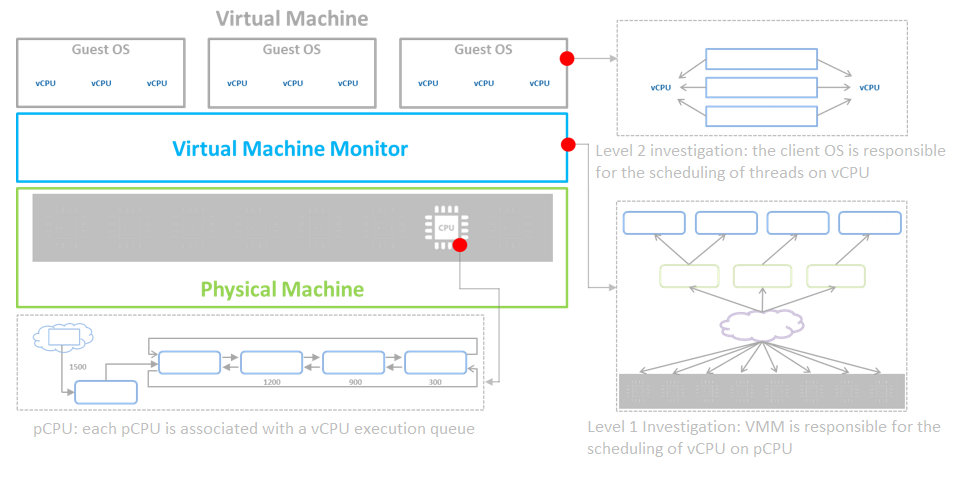
The aSV platform virtualizes CPU, memory, and IO devices through VMM (Virtual Machine Monitor).
Based on hardware-assisted virtualization technology, aSV uses VMM to realize the virtualization of x86 architecture and divides a single physical CPU into multiple vCPU. The virtual machine only sees the vCPU presented by VMM and does not directly perceive the physical CPU. The user operating system is responsible for the level 2 schedule, the scheduling of threads or processes on vCPU. The virtual machine monitor is responsible for the level 1 schedule and the scheduling of vCPU on the physical processing unit.
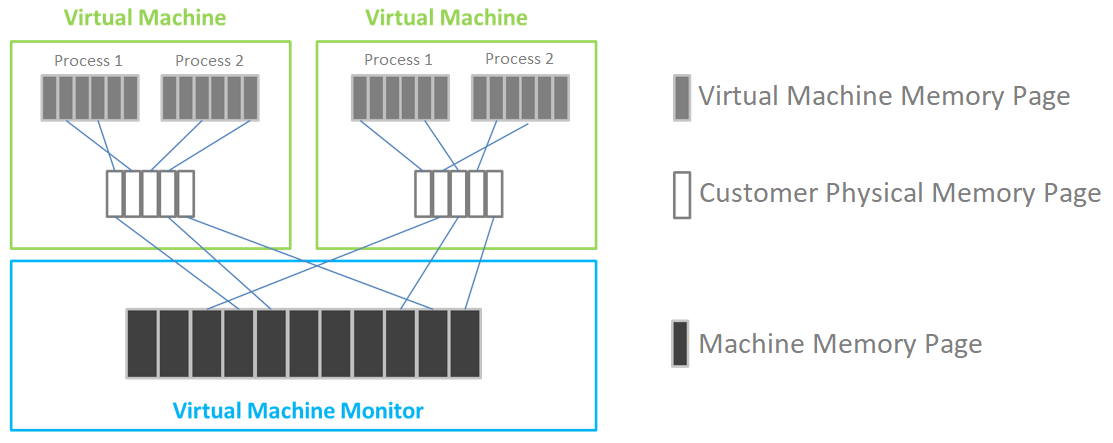
aSV completes memory virtualization based on page table virtualization technology. VMM is responsible for page memory management, maintaining the mapping relationship from virtual address to machine address, virtualizing physical memory into the virtual machine, and using virtual memory.
aSV uses VMM to intercept the access request of Guest OS to I/O devices and then simulates the real hardware through software to realize I/O virtualization.
aSV supports hot addition to the CPU and memory of the virtual machine and hot plug to the interface and disk of the virtual machine.
The automation strategy provided by the automated hot addition function can quickly respond to the growth and change of the business state. Dynamically expand the virtual machine's CPU and memory resources, ensuring business continuity and solving the agile operation and maintenance problems caused by user business growth.
Virtual machine high availability (HA) is divided into node failure HA and virtual machine failure HA.
• Node failure HA means that when the node where the virtual machine is located has an accident (node power outage, interface drop, etc.), a node with sufficient resources will be selected to restart the virtual machine, which significantly reduces the service interruption time.
• Virtual machine failure HA refers to shutting down the virtual machine and restarting it on the original physical node when the virtual machine has a blue screen, black screen, and other failures.
The rapid recovery function can immediately create and start the virtual machine when it needs to be restored. The process can be completed in 3 minutes, and the performance will climb to the normal within 15 minutes, which can quickly help users restore business operation and ensure business continuity. RTO <= 15 minutes.
By modeling the core business database and using an AI algorithm, the NUMA binding rule base of the core database in the general scenario is generated to improve the business performance.
By isolating the memory area of each module, the system will not be suspended or shut down due to memory preemption to improve the platform's reliability. At the same time, it supports the over allocation of virtual machine CPU and memory, and the actual usage can exceed the physical limit. Give priority to ensuring the memory usage of important virtual machines and improving the CPU and memory usage.
Monitor whether the system disk and memory of the node in the cluster are in the sub-health state, give treatment opinions to the sub-health node and reduce the priority of the sub-health node in the process of virtual machine startup (or HA) node selection. Currently, it supports processing five sub-health states: memory CE and UE errors on the node, read-only system disk, insufficient SSD lifetime, and bad channel on HDD.

 {{ $t('index.defaultHeader.chromeBrowserTip') }}
{{ $t('index.defaultHeader.chromeBrowserTip') }}