{{ secondMenu.name }}





Function Description:
HCI can automatically identify and display unhealthy nodes (hung nodes or nodes with the hang risk) and does not prefer them for VM startup, HA, and other tasks. For cluster capacity expansion, node replacement, and other scenarios, SCP will detect the hardware to prevent node crash or system hang due to hardware failure to reduce the business service risks.
Precautions:
Prerequisite:
None.
Steps:
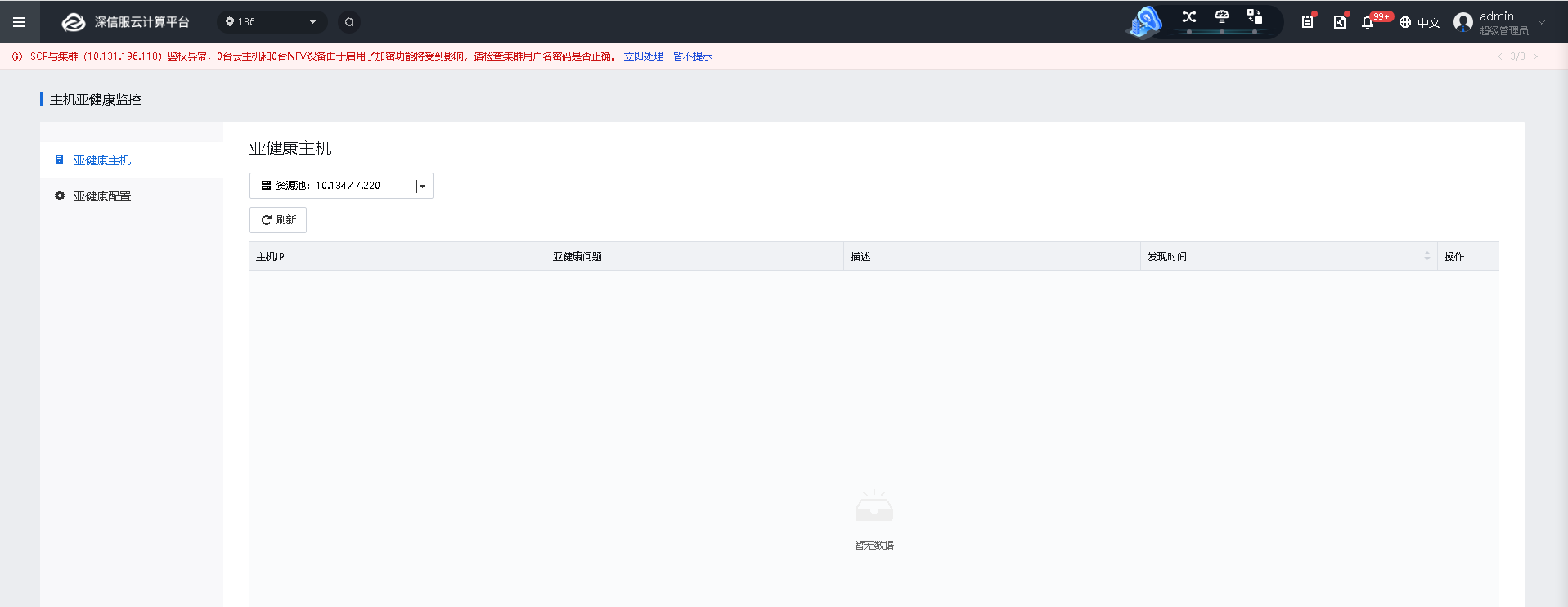
Step 1.Log in to SCP, and go to Resources > Reliability > Host Health Monitoring > Unhealthy Nodes to view unhealthy physical hosts.
Step 2.Go to Health Monitoring to configure Host Health and Network Health.
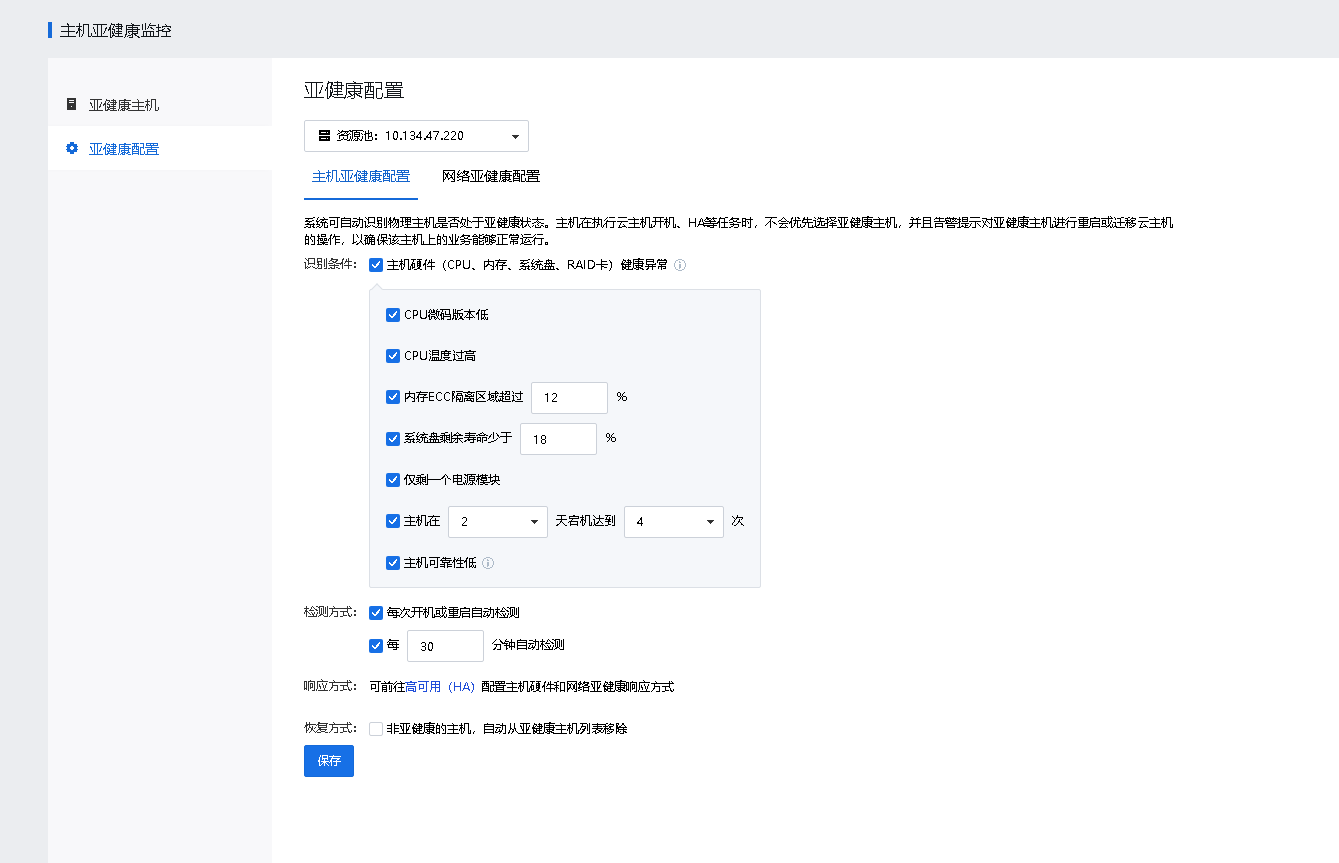
• Unhealth Metrics: If Host hardware (CPU, memory, system disk or RAID card) anomaly is enabled, the following will be checked: ECC Memory, UECC Memory, Bad Sector in System Disk, System Disk Read-Only, Short System Disk Lifetime Remaining, and RAID Card Failure. You can customize the crash frequency to identify unhealthy nodes that meet the criteria.
• Check Schedule: If Health Monitoring is enabled, the check will be automatically performed at each host startup or restart. You can also customize the check interval.
• Notification Method: You can go to Resources > Monitor Center > Alerts > Notification Policies to configure the email notification by referring to Section 4.12.3.2 Alert Options. When an unhealthy node is detected, the platform will send an email to notify the check results.
• Recovery Method: You can go to Resources > Reliability > HA to configure recovery methods for host hardware failures.
• Fixing Method: This mechanism will only migrate VMs on unhealthy nodes to healthy nodes. VMs that have been configured with a scheduling policy are prioritized to be scheduled based on the scheduling policy, and VMs without a scheduling policy will only be migrated to unhealthy nodes that are relatively healthy. This mechanism does not take effect if there are no healthy nodes in the cluster and does not apply to NFV devices.
• Auto Removal: If enabled, unhealthy nodes will be automatically removed from the Unhealthy Nodes list when they are healthy again.
Function Description:
The network health check of HCI detects the packet loss and latency of the network links through messages sent between nodes. When the packet loss rate or latency reaches the threshold, an alert will be generated to effectively prevent service interruptions due to link issues.
Precautions:
None.
Prerequisite:
|
|
Aggregated |
Non-Aggregated |
Aggregated and Non-Aggregated |
| Management Interface |
√ |
√ |
√ |
| Overlay Network Interface |
√ |
√ |
√ |
| Edge-Connected Interface |
√ |
√ |
√ |
| Storage Network Interface |
√ |
√ |
× |
| aDesk Communication Interface |
√ |
√ |
√ |
• Network links between SCP and HCI.
• Communication network of witness nodes (2+1 witness nodes, stretched cluster + witness node).
• Heterogeneous clusters (VMware) either links between HCI clusters and heterogeneous clusters.
• Physical hosts managed by SCP.
Steps:
Step 1.Log in to SCP, go to Resources > Reliability > Host Health Monitoring > Health Monitoring > Network Health to configure Packet Loss and Latency for interfaces. When their thresholds are reached, alerts will be generated.
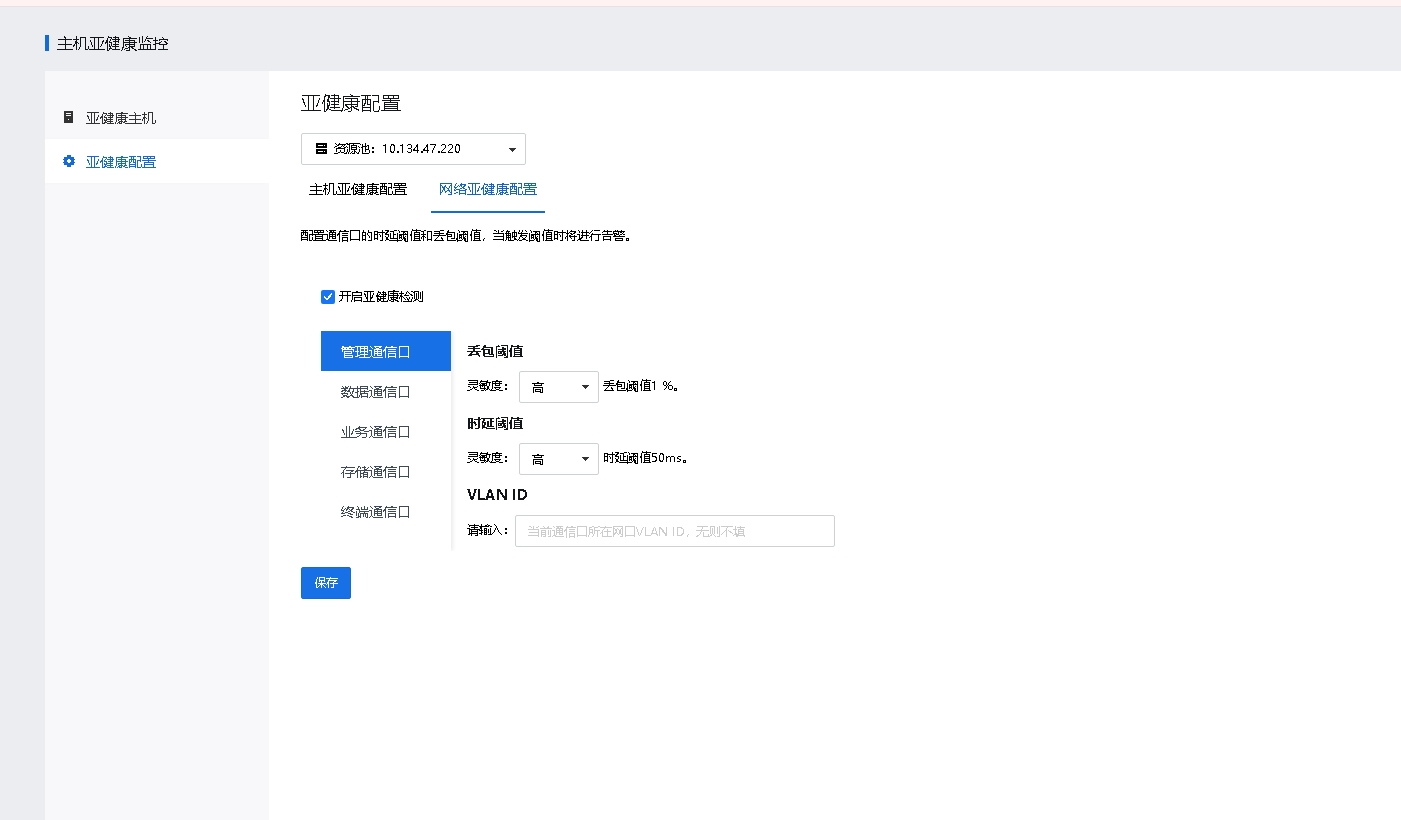
The following are the interface configuration references:
| Interface Type |
Low Sensitivity |
Medium Sensitivity |
High Sensitivity |
Check Time Range |
Alert Interval |
Max Alert Cancellation Time after Network Recovery |
| Management Interface |
Packet Loss Rate ≥ 10% Latency ≥ 120 ms Check Interval=1 time/s |
Packet Loss Rate ≥ 5% Latency ≥ 75 ms Check Interval=1 time/s |
Packet Loss Rate ≥ 1% Latency ≥ 50 ms Check Interval=2 times/s |
3 minutes |
1 minute |
4 minutes |
| Overlay Network Interface |
Packet Loss Rate ≥ 10% Latency ≥ 120 ms Check Interval=1 time/s |
Packet Loss Rate ≥ 5% Latency ≥ 75 ms Check Interval=1 time/s |
Packet Loss Rate ≥ 1% Latency ≥ 50 ms Check Interval=2 times/s |
3 minutes |
1 minute |
4 minutes |
| Edge-Connected Interface |
Packet Loss Rate ≥ 10% Latency ≥ 120 ms Check Interval=1 time/s |
Packet Loss Rate ≥ 5% Latency ≥ 75 ms Check Interval=1 time/s |
Packet Loss Rate ≥ 1% Latency ≥ 50 ms Check Interval=2 times/s |
3 minutes |
1 minute |
4 minutes |
| Storage Network Interface |
Packet Loss Rate ≥ 0.2% Latency ≥ 1.2 ms Check Interval=10 times/s |
Packet Loss Rate ≥ 0.1% Latency ≥ 850 us Check Interval=10 times/s |
Packet Loss Rate ≥ 0.04% Latency ≥ 500 us Check Interval=10 times/s |
15 minutes |
1 minute |
4 minutes |
| aDesk Communication Interface |
Packet Loss Rate ≥ 2% Latency ≥ 50 ms Check Interval=1 time/s |
Packet Loss Rate ≥ 1% Latency ≥ 25 ms Check Interval=1 time/s |
Packet Loss Rate ≥ 1% Latency ≥ 5 ms Check Interval=2 times/s |
3 minutes |
1 minute |
4 minutes |

 {{ $t('index.defaultHeader.chromeBrowserTip') }}
{{ $t('index.defaultHeader.chromeBrowserTip') }}